Deploy & Query Llama2-7B on Sagemaker
This tutorial has 2 major components:
- Deploy Llama2-7B on Jumpstart
- Use LiteLLM to Query Llama2-7B on Sagemaker
Deploying Llama2-7B on AWS Sagemaker
Pre-requisites
Ensure you have AWS quota for deploying your selected LLM. You can apply for a quota increase here: https://console.aws.amazon.com/servicequotas/home
- ml.g5.48xlarge
- ml.g5.2xlarge
Create an Amazon SageMaker domain to use Studio and Studio Notebooks
- Head to AWS console https://aws.amazon.com/console/
- Navigate to AWS Sagemaker from the console
- On AWS Sagemaker select 'Create a Sagemaker Domain'

Deploying Llama2-7B using AWS Sagemaker Jumpstart
After creating your sagemaker domain, click 'Open Studio', which should take you to AWS sagemaker studio
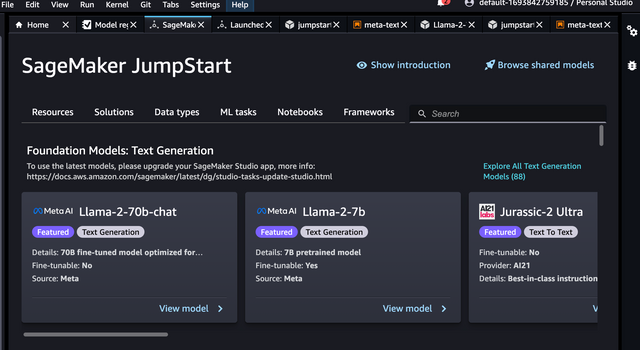
On the left sidebar navigate to SageMaker Jumpstart -> Models, notebooks, solutions
Now select the LLM you want to deploy by clicking 'View Model' - (in this case select Llama2-7B)
Click
Deployfor the Model you want to deploy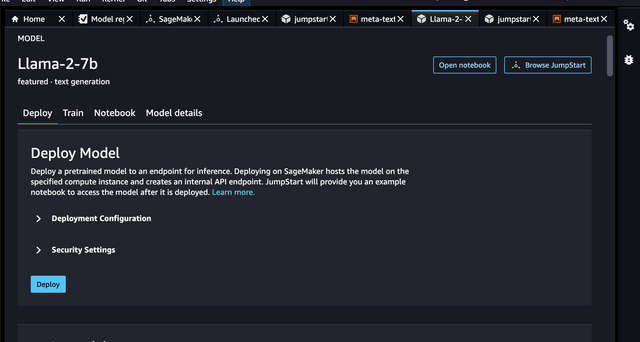
After deploying Llama2, copy your model endpoint
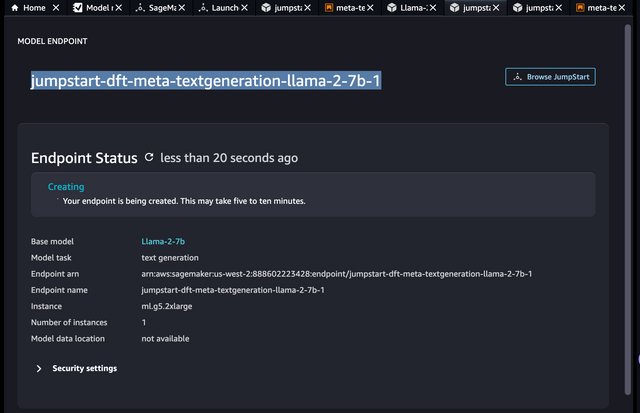
Use LiteLLM to Query Llama2-7B on Sagemaker
Prerequisites
pip install boto3pip install litellm- Create your AWS Access Key, get your
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY. You can create a new aws access key on the aws console underSecurity Credentialsunder your profile
Querying deployed Llama2-7b
Set model = sagemaker/<your model endpoint> for completion. Use the model endpoint you got after deploying llama2-7b on sagemaker. If you used jumpstart your model endpoint will look like this jumpstart-dft-meta-textgeneration-llama-2-7b
Code Example:
from litellm import completion
os.environ['AWS_ACCESS_KEY_ID'] = "your-access-key-id"
os.environ['AWS_SECRET_ACCESS_KEY'] = "your-secret-key"
response = completion(
model="sagemaker/jumpstart-dft-meta-textgeneration-llama-2-7b",
messages=[{'role': 'user', 'content': 'are you a llama'}],
temperature=0.2, # optional params
max_tokens=80,
)
That's it! Happy completion()!
Next Steps:
- Add Caching: https://docs.litellm.ai/docs/caching/gpt_cache
- Add Logging and Observability to your deployed LLM: https://docs.litellm.ai/docs/observability/callbacks